Suggested posts prior to reading this one:
- A Cautionary Tale: The Bias-Variance Tradeoff in Machine Learning
- Guide: Cross Validation with Julius
Introduction
Least Squares Regression is a fundamental technique in machine learning and statistics used to model the relationship between a dependent variable and one or more independent variables. By minimizing the sum of squared residuals, Least Squares Regression finds the best-fitting line or hyperplane that describes the relationship between the variables.
In this post, we’ll explore how to perform Least Squares Regression using Julius, through natural language interactions only. We’ll walk through a comprehensive example to demonstrate Julius’ capabilities and highlight the ease with which you can conduct regression analysis using this innovative tool.
Example: Fuel Consumption and CO2 Emissions
To showcase the power of Julius in performing Least Squares Regression, let’s consider a simple but informative example involving the relationship between fuel consumption and CO2 emissions in vehicles.
Loading and Exploring the Dataset
I began by asking Julius to load the “fuel_consumption_1.csv” dataset and provide a description of its contents. To gain a deeper understanding of the data, I requested descriptive statistics and histograms from Julius. In a matter of seconds, Julius generated informative visualizations and provided key statistical measures, allowing me to assess the distribution and characteristics of the variables effortlessly.

Julius’ ability to quickly load and describe datasets through natural language queries streamlines the initial stages of data exploration, saving valuable time and effort.
##3 Investigating the Relationship
Before diving into regression analysis, it’s crucial to understand the relationship between the variables. I asked Julius to calculate the correlation coefficient and create a scatter plot to visualize the relationship between fuel consumption and CO2 emissions.
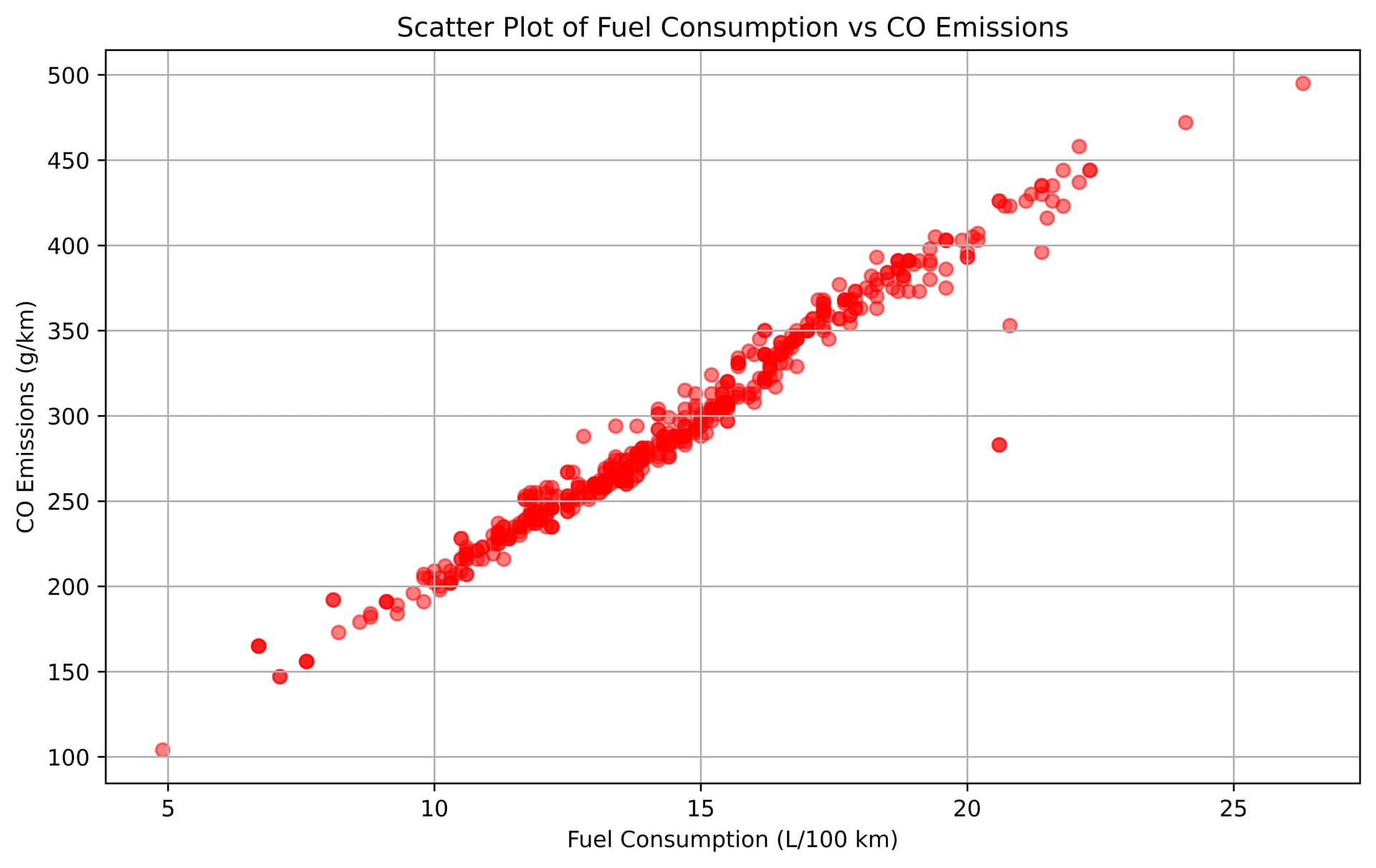
Julius swiftly provided the correlation coefficient of 0.981, confirming a strong positive relationship between the variables. The scatter plot generated by Julius clearly illustrates this relationship, with data points forming a distinct upward trend. As you can see, not that interesting of a dataset because the relationship is immediately visually clear, but it helps me demonstrate the ease of using natural language to perform regressions with Julius.
Building the Least Squares Regression Model
With a solid understanding of the data, I proceeded to build a Least Squares Regression model using Julius. I requested an 80-20 train-test split and asked Julius to train the model on the training set.
Julius efficiently split the data and trained the model, providing the model’s coefficients and intercept. The high R² score of 0.977 on the test data indicated the model’s strong predictive power, achieved with minimal effort through natural language interaction.
Evaluating Model Performance
To assess the model’s performance, I asked Julius to calculate various evaluation metrics, including Mean Squared Error (MSE), Mean Absolute Error (MAE), and R-squared, on the test data.

Julius quickly computed these metrics, confirming the model’s effectiveness with low error values and a high R-squared, demonstrating the ease with which model evaluation can be conducted using Julius.
Cross-Validation and Residual Analysis
To ensure the model’s robustness and identify potential issues, I requested Julius to perform Leave-One-Out Cross-Validation (LOO CV) and visualize the residuals.

Julius conducted the LOO CV and provided the average performance metrics, giving me confidence in the model’s stability. The residuals chart generated by Julius allowed for a visual inspection of the model’s assumptions and potential heteroskedasticity.
Interpreting the Model
To gain insights into the model’s implications, I asked Julius to provide the fitted parameters and interpret them in the context of the problem.

Julius explained the meaning of the intercept and slope, highlighting the baseline CO2 emissions and the rate of increase with each additional unit of fuel consumption, respectively. This interpretation, obtained through a simple query, enhances the understanding of the model’s results and their practical significance.
Predicting on New Data
To demonstrate the model’s predictive capabilities, I provided Julius with a new dataset, “fuel_consumption_2.csv,” and requested predictions and performance comparisons.

Julius effortlessly loaded the new dataset, applied the trained models, and calculated the MSE for each model’s predictions, showcasing the consistency and accuracy of the Least Squares Regression model built with its assistance.
Conclusion
Through this comprehensive example, we witnessed the power and simplicity of performing Least Squares Regression using Julius. By leveraging Julius’ natural language processing capabilities, we were able to efficiently load and explore data, build and evaluate regression models, and interpret the results, all with zero coding effort.
Julius’ ability to understand and respond to natural language queries streamlines the entire regression analysis process, making it accessible to users with varying levels of technical expertise. Its seamless integration of data visualization, model training, evaluation, and interpretation functionalities enables users to focus on the insights and outcomes rather than getting bogged down in the intricacies of coding.
Keywords: Least Squares Regression, Julius, AI-powered assistant, natural language interaction, data analysis, model building, fuel consumption, CO2 emissions, data visualization, model evaluation, cross-validation, residual analysis, model interpretation, predictive capabilities