Picture this: you’re bringing in your dataset, running those descriptive statistics to get an idea of the characteristics, and everything is going fine. Then you move onto testing normality and homogeneity of variances and “BAM”, Julius gives you this:

OH NO! Both my normality and homogeneity of variances are statistically significant, indicating that my data does not follow normal distribution. This outcome suggests that we cannot run parametric tests… so what now?
Luckily, there are tests that can handle data that violates these assumptions, and guess what they are called? Non-parametric tests! This guide will go over some of the different non-parametric tests you can run on Julius and how to interpret the outcomes.
Common Non-parametric Tests
1. Kruskal-Wallis
This is a non-parametric alternative to the one-way ANOVA. It is used for comparing medians of three or more independent groups.
Example:
You want to look at the impact of different fertilizer treatments on three groups of plants (group_a, group_b, and group_c). Each group contains 15 plants that were randomly assigned a treatment.
| group_a | group_b | group_c |
|---|---|---|
| 4 | 8 | 5 |
| 1 | 2 | 14 |
| 3 | 5 | 12 |
| 3 | 8 | 8 |
| 1 | 4 | 7 |
| 2 | 1 | 7 |
| 1 | 4 | 9 |
| 1 | 5 | 13 |
| 2 | 4 | 7 |
| 2 | 3 | 11 |
| 1 | 4 | 11 |
| 0 | 8 | 10 |
| 4 | 2 | 13 |
| 2 | 2 | 14 |
| 1 | 2 | 9 |
Descriptive statistics were already run on this dataset, which are as follows:

This dataset violates the test for normality as well as levene’s test for homogeneity of variances:

We can also see that the whiskers from the box plot are very exaggerated for each group, and the median does not fall directly in the centre of the box itself:
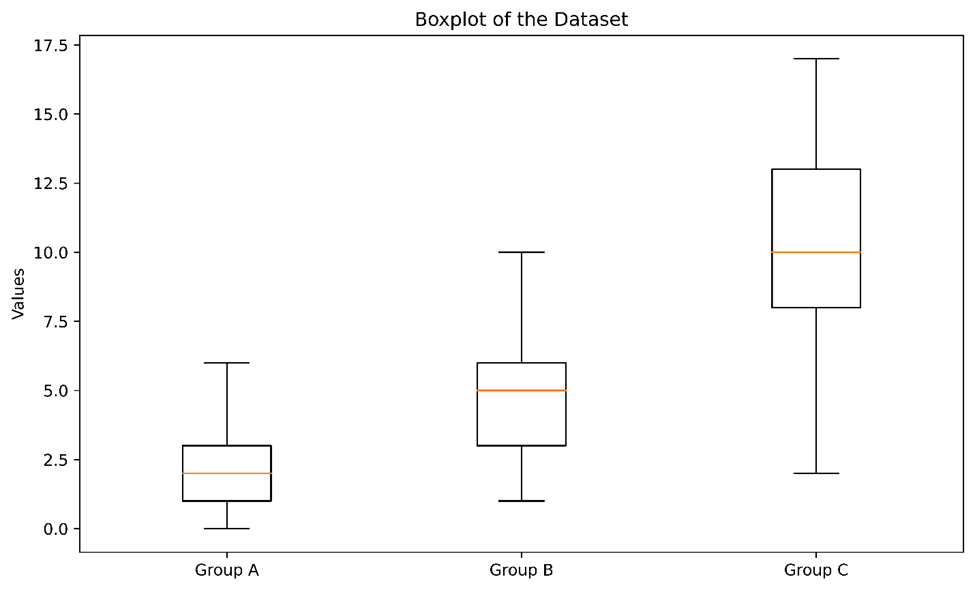
You can try to transform your data using different techniques (log transformation, square root transformation, exponential transformation, etc.) to avoid using non-parametric tests altogether. However, for this guide, I’m going to assume that this data fails those transformations to simplify this.
Now that we have run both normality and homogeneity tests, as well as visualized the data, let’s ask Julius to run a Kruskal-Wallis test:
Question 1: Are there any statistically significant differences in growth rates amongst the three soil types?
Prompt 1: Can you perform a Kruskal-Wallis test to determine if there are statistically significant differences between growth rates between group_a, group_b, and group_c?

Question 2: Where are these differences located? What post-hoc test should I use?
Prompt 2: What post-hoc tests can be used to determine specific group differences and what one do you suggest for my dataset?

Question 3: Perform a post-hoc test to determine differences amongst groups.
Prompt 3: Can you run a Dunn’s test to determine where the specific differences are between group_a, group_b and group_c?

These results show that groups A and B are not statistically significant from one another. However when comparing both A and B to group C, they are significantly different. Let’s create a graph showing this:

I had to do some additional prompting because my original graph had the lettering above mixed in with the standard error bars. I prompted it with the following to move the letters above the standard error bars: “move lettering above standard error bars”. This approach lets the reader know that the same lettering above the graphs indicates non-significant results, while a different letters indicates statistically significant results. This means that Group A and B are not statistically significant from one another, but Group C is.
Finally, you can report your test results as follows:
“The Kruskal Wallis test was used to examine differences in plant growth between three soil treatments. Results indicated that there was a statistically significant difference between soil treatments on plant growth (H=209.97, df=2, p<0.05). Further post hoc testing revealed statistically significant differences between Group A and C (p<0.001) and Group B and C (p=0.002). However, no statistically significant difference was reported between Groups A and B (p>0.05).”
As an aside: I had issues running the Dunn’s post hoc test, so I had to manually insert coding in the chat box. This was the code I used for this dataset:
#Create DataFrame, takes the data I have in my excel spreadsheet and manually enters it into python
data = {
‘group_a’: [4, 1, 3, 3, 1, 2, 1, 1, 2, 2, 1, 0, 4, 2, 1],
‘group_b’: [8, 2, 5, 8, 4, 1, 4, 5, 4, 3, 4, 8, 2, 2, 2],
‘group_c’: [5, 14, 12, 8, 7, 7, 9, 13, 7, 11, 11, 10, 13, 14, 9]
}
df = pd.DataFrame(data)
#Kruskal-Wallis test, runs the Kruskal test on the created dataset
kw_stat, kw_pval = kruskal(df[‘group_a’], df[‘group_b’], df[‘group_c’])
print(“Kruskal-Wallis Test:”)
print(“Test Statistic:”, kw_stat)
print(“P-value:”, kw_pval)
#Dunn’s test (post-hoc) runs the post hoc test on the dataset
if kw_pval < 0.05: # If Kruskal-Wallis test is significant
posthoc_dunn_result = posthoc_dunn(df, val_col=‘value’, group_col=‘groups’, p_adjust=‘bonferroni’)
print(“\nDunn’s Test (post-hoc):”)
print(posthoc_dunn_result)
2. Mann-Whitney U Test
This test is used to compare the medians of two independent groups when the assumption of normality is violated.
Example:
You want to look at the effectiveness of a new mRNA vaccine on the seasonal flu. A pilot trial randomly assigns patients to a treated or untreated group (n=50). They assessed the viral load (quantity of virus (10^-2 result) per mL of blood) in the treated versus untreated group. The data is shown below:
| Treated | Untreated |
|---|---|
| 5.466757 | 8.688862 |
| 4.240556 | 6.09494 |
| 5.807066 | 5.267411 |
| 8.241744 | 10.03258 |
| 4.080986 | 12.37279 |
| 4.081013 | 11.77101 |
| 8.429059 | 4.856856 |
| 6.091985 | 6.330592 |
| 3.714374 | 8.720109 |
For simplicity reasons, I only included the first 10 rows since this dataset is relatively large. The following results were already determined:



Question 1: Is there any statistical significance between the two groups?
Prompt 1: Explore non-parametric tests for comparing the treated and untreated groups.

I used this prompt to show you that Julius can give you multiple test results for this dataset. However, since these results are NOT paired, we cannot use the Wilcoxon Signed-Rank test result, and since we have only two independent groups, it would be wise to choose the Mann-Whitney U Test.
Prompt 2: Can you provide the best data visualization for these results please?

I prompted incorrectly, because Julius thought I was talking about comparing the three statistical analyses together. Instead, I wanted a data visualization of the comparison between the treated and untreated group. So, let’s re-prompt:
Prompt 3: Sorry, let me rephrase: can you provide a data visualization for the comparison of the treated versus nontreated group, please?

Perfect, now let’s ask Julius to recap the findings of our study:
Prompt 4: Can you provide a summary of the key findings from the comparison of the treated and untreated groups?

Finally, we can report our findings from the Man-Whitney U test:
“Median values in the treated and untreated groups showed significant differences, with the Man-Whitney U Test revealing a statistic of 564.0 (n1 = n2 = 50, p < 0.05, two tailed). This indicates a significant effect of the treatment on viral amount in patients, with untreated having on average a higher viral load (10.13±1.49) than the treated patients (4.39±0.24).
Last minute remarks: You can also prompt Julius to estimate the effect size of the measures from various tests you run. For example, let’s look at the effect size found between the treated and untreated groups from Mann-Whitney U test:

This is just another way for you to really dive into the nitty gritty of your results. For this particular outcome, we see that there is a moderate to strong positive effect size (0.549), with the treated group tending to have lower scores compared to the untreated group. This additional analysis is perfect to add in when explaining your results.
Keywords: AI statistical analysis, AI statistics, GPT, Non-parametric, Kruskal-Wallis, Mann-Whitney U, normality test, homogeneity of variances, descriptive statistics, data visualization, statistical analysis